
Open Source LLMs are Surprisingly Good
We can already replace GPT-4 with locally-run models in some products. Benchmarks help to pinpoint opportunities for migration. Results get only better over time.
In the past, we’ve talked about GPU shortages and how this affects major providers of GPT. It is difficult to get access to Azure OpenAI, Anthropic, or AWS Bedrock.
While large companies can’t keep up with the demand (and grow by serving it), innovation doesn’t stop in the realm of open models. There is a whole ecosystem growing. The killer feature here - customers can bring their hardware to run these models.
Here, for example, is a screenshot of my laptop running a compressed (quantised) version of Vicuna-13B in CPU-only mode:

13B here refers to the complexity of the model - number of variable parameters that were configured during the training phase. Models with more parameters are generally more capable.
As you can see, this model is quite capable. It was able to perform a specific task of extracting product property from the text.
What if we wanted to see how suitable are different large language models for building different products?
Trustbit LLM Product Benchmark
If you zoom out at look at the entire landscape of language models across a matrix of their capabilities, you’ll see something like the image below.
This is a preview of the Trustbit LLM Product Benchmark. It focuses on the ability of large language models to support software products with LLM under the hood.

This is only a preview. Larger and more interesting LLM models will be covered in the full report, to be published on the website of Trustbit.
There are two key takeaways. First of all, Chat GPT-4 is still the best model. Use it to start prototyping new products.
Second, the competition is indeed catching up. Even smaller models like Vicuna 13B can already perform quite well in some products. Especially in the categories of:
documents - working with large documents and knowledge bases;
CRM - working with product catalogs and marketplaces.
If something is not working out, an excellent strategy for improving results is “wait for one more week and evaluate state-of-the-art models again”.
Let’s zoom out even more, and look at two additional LLM leaderboards. Each focuses on a different subset of the LLM ecosystem and uses a different methodology.
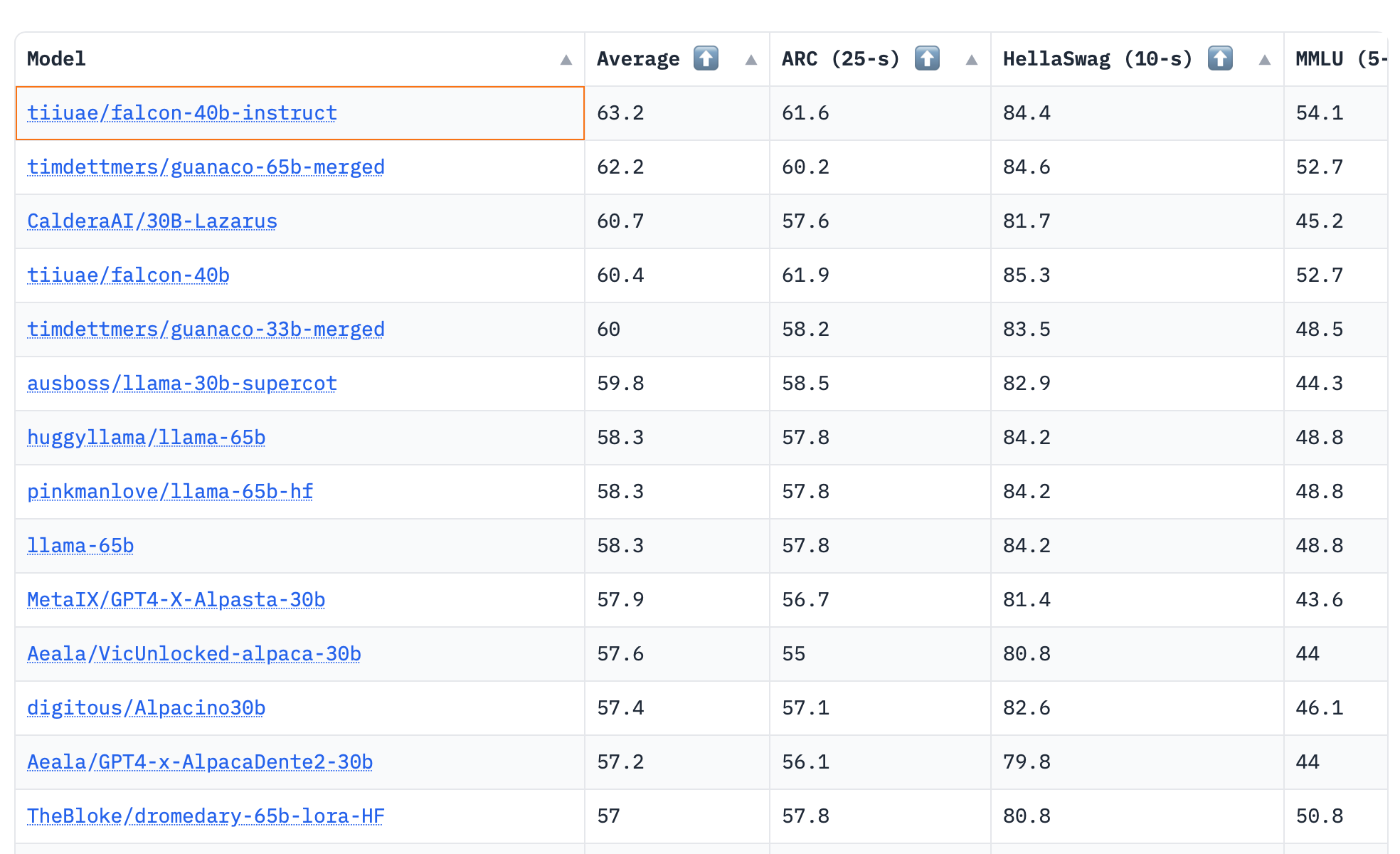
First, HuggingFace leaderboard of open LLM models:
Then, another leaderboard from lmsys:

Smaller models (30B and 40B) are beating previously uncontested 65B LLaMA
New model names keep on popping up, pushing Vicuna (which ranked quite high before) far down.
While this dashboard looks like a wild zoo of diverse models, there is even more diversity behind the scenes.
Diversity Behind the Scenes
Let’s take a deeper look at the 30B-Lazarus model (3rd place on HuggingFace). Did you know that there are at least 15 flavours of that model?
Original model, roughly at 66GiB size.
14 quantized versions in ggml format, from 34GB down to 13GB.
Quantisation is about compressing the LLM weights at the cost of some accuracy. 40B model compressed down can work better than the 13B model of the same size. It could also be faster.
So, why are there 14 different versions of a single 30B-Lazarus model? Everybody wants to run the best model that fits their hardware. People pick the model that works the best in their case.
All this creates a form of evolutionary pressure on the landscape of large language models.
Large companies don’t have the hardware capacity to provide foundational models as a service to everybody. This will hinder their growth for some time.
If possible, people prefer to avoid using hosted models completely, to avoid vendor lock-in and maintain privacy.
If you control the model, you can fine-tune it or provision enough hardware to satisfy your demand. There are options.
Small local models enable new forms of remixing and collaboration, pushing the innovation even further.
If you are building products powered by LLMs, it is worth to start looking into local language models, just to build up the intuition.
An easy way to get started is:
Install llama.cpp (command-line) or oobabooga (fancy web UI)
Grab a GGML model from HuggingFace, for instance vicuna-13B. Pick the smallest one for the first iteration of your experiment, then switch to a larger flavour.
Ask LLM your question and share how it went :)