
Breaking the curse of LLM v2
New releases of large language models focus on efficiency. Sometimes quality is sacrificed. LLaMA v2 was a nice surprise.
In June I wrote a newsletter about GPU starvation in major LLM/GPT providers. Companies were trying to make their models run faster and use less hardware. This affected development of their produces.
Let’s talk about new versions GPT-4, Claude and LLaMA v2.
OpenAI GPT 0613 Update
GPT-4 API got the first major update since march. The notable features there is Javascript function calling. As OpenAI announced:
These models have been fine-tuned to both detect when a function needs to be called (depending on the user’s input) and to respond with JSON that adheres to the function signature. Function calling allows developers to more reliably get structured data back from the model.
Similar change also applies to GPT-3.5-Turbo. Both models are “updated and improved”, according to the documentation.
However, if you dig deeper, the major improvement seems to be about the performance of these models, while quality stays the same. In some cases, it could even get worse.
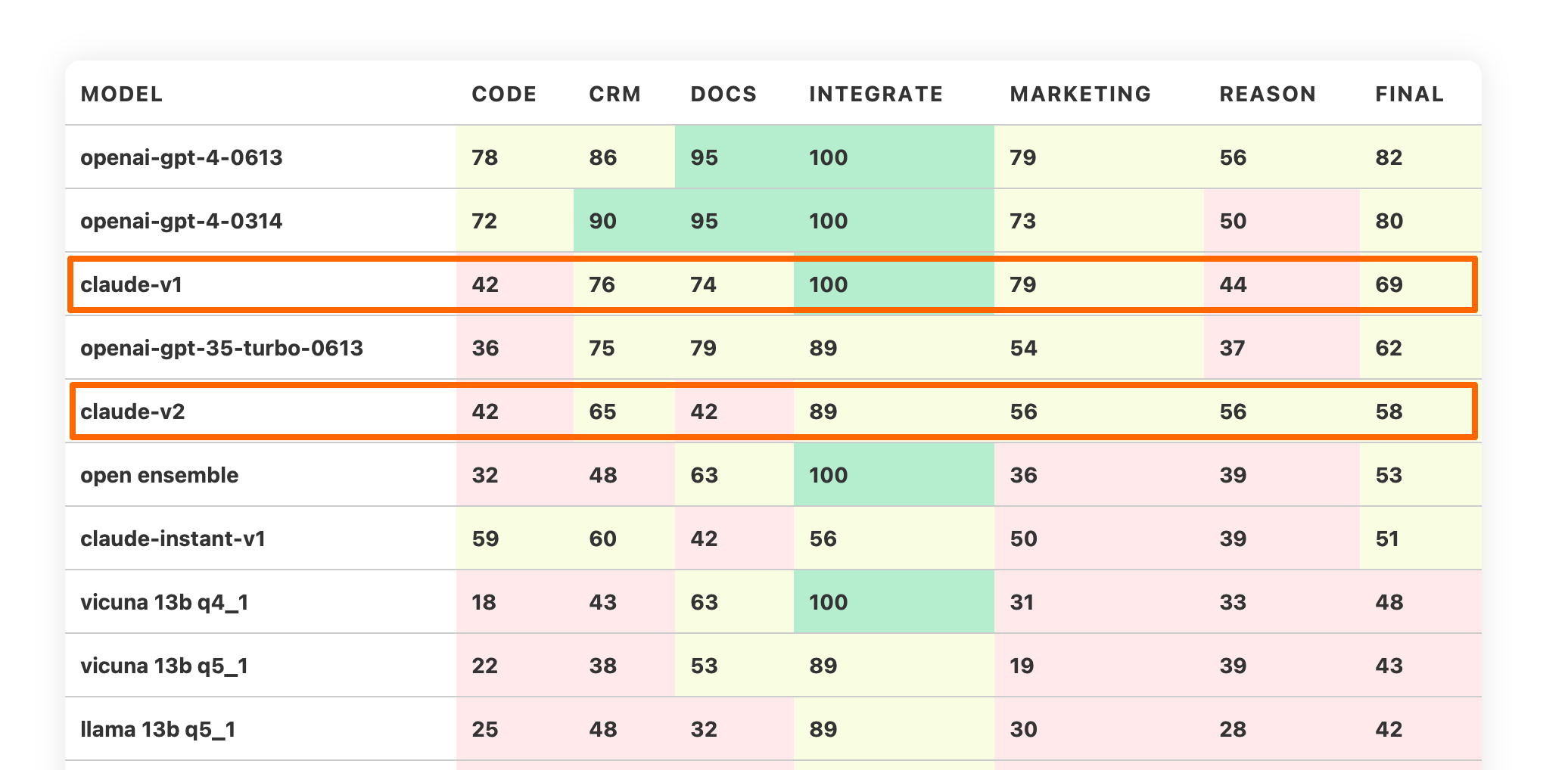
Preliminary results of Trustbit LLM Product benchmarks show that GPT-4 got much better in “code”, “marketing” and “reasons” tasks, while tasks related to automating business processes around CRM systems - got worse.

Refuel AI also notes a similar trend:
We found that the new gpt-3.5-turbo model had poorer labeling quality on six out of eight datasets. However, the new model is significantly faster (~40% lower turnaround time). The labeling performance for the gpt-4 model was more or less the same.
So if we focus on model quality, jump from GPT-4 API v0314 to v0613 is not even a jump, but more like a limp.
Anthropic Claude v2
Anthropic similarly focused on performance in Claude v2, as well: “Claude 2 has improved performance, longer responses”.
Quality of the new model has got worse on product benchmarks:
LLaMA v2
It looks like Meta (Facebook) did manage to break the curse of the subpar second release, though.
The second version of LLaMA was just announced:
More permissive license, that allows commercial use (see gotchas below)
Better quality.
Includes variants of 7B, 13B and 70B (huge).
Meta also made a really smart move. They kept model architecture similar to v1. This allows to leverage all the infrastructure and tools that community have already built.
If you have read my previous newsletter on the Cambrian explosion - now we are witnessing start of another spiral.
Model compatibility has already enabled the community to start porting LLaMA v2 binary files to GGML format that can run on CPU.

There are a few gotchas about the license, though.
First one - companies with more than 700M monthly users can use model only if Meta allows that. That is so anti-Google.
Second one comes from the Model card. Working in English is in scope. Any other language - out of scope. That is a serious blow, especially for the minor languages.

Meta claims that it has invested a lot of effort in safety and guardrails. Probably most that effort went in the English language, so they just added this clause to avoid being liable for any other languages.
Expect updated benchmarks with LLaMAv2 to be published closer to the end of the month.