
New ChatGPT models and ML product cases
Let’s recap the most notable events. We’ll start with the tech highlights, then talk about ML products that companies want to build, problems and solutions.
Hi,
what a week this has been, right?
Let’s recap the most notable events. We’ll start with the tech highlights, then talk about ML products that companies want to build, problems and solutions.
Tech highlights
- OpenAssistant had been released. This is essentially a training dataset (instruct GPT) that is applied to tune available LLM models. They say that results are comparable with Chat GPT3.5
- Databricks gathered its own training dataset and released Dolly. That is another LLM tuned with instruction following, based on Pythia model.
- Elon Musk bought 10k GPUs and started an AI company. Probably that open letter to stop AI research didn’t work out for him
- Amazon partnered with a couple of ML companies to offer their models on AWS platform: StabilityAI, AI21Labs and Anthropic (link). This is a smart move to try catching up with Azure+OpenAI! They have also made Codewhisperer (equivalent of GitHub Copilot) available for free.
There are new cool and compact applications of ChatGPT that demonstrate the power of plugins and agents. Check them out!
BabyAGI - demo of a task-driven autonomous agent where core logic fits into a single file.
AI Brainstore - impressive and compact demo of a memory for an AI agent. It tries to answer questions from its memory, pulling new insights from google, if absent.
This is the important part of the tech news.
Product and Business highlights
From my involvement with Trustbit and Endangered Languages projects, I saw a lot of movement on the radar. Companies across industries (banking, logistics, retail) are essentially asking two questions:
- How can we build a smart agent/pipeline to solve this problem X?
- We can’t trust the cloud. How can we run everything on-the-premises?
Let’s try to answer these two. There is no point in keeping the trade secrets, because:
(1) the devil is still in the details;
(2) approaches and architectures get drastic improvements every week, so secrets get stale.
How can we build a smart agent/pipeline to solve this problem X?
Different businesses have different nuances. All of the problems tend to fall along these lines:
Our website search with Elastic/Lucene/Cognitive - sucks. It returns a dozen of useless suggestions, based on keyword matches. How do we return only a few answers that make sense?
How can we build an interactive smart chat that is capable of using our company data/services to answer questions?
How do we transform messy data into structured data that fits our systems? How do we convert incoming PDFs and emails to new items in our “Business workflow system X”? How do we create quality product listings by using interactive user input, web search results and image recognition?
Short answers to each one:
See LangChain. Use ada-2 for the embeddings, good vector database and benchmark various indexes from LLamaIndex to get the best information retrieval results.
Same as above, but also keep an eye on plugins (to interact with the other systems) and additional agents with memory. Please add feedback loop for the users to rate answers and gather ALL feedback and responses. You’ll need them to train better models later.
All of the above, with the focus on good prompt engineering, plugins and LangChain.
While we are talking about LangChain, vector databases and information retrieval, here is how the entire architecture could look like:
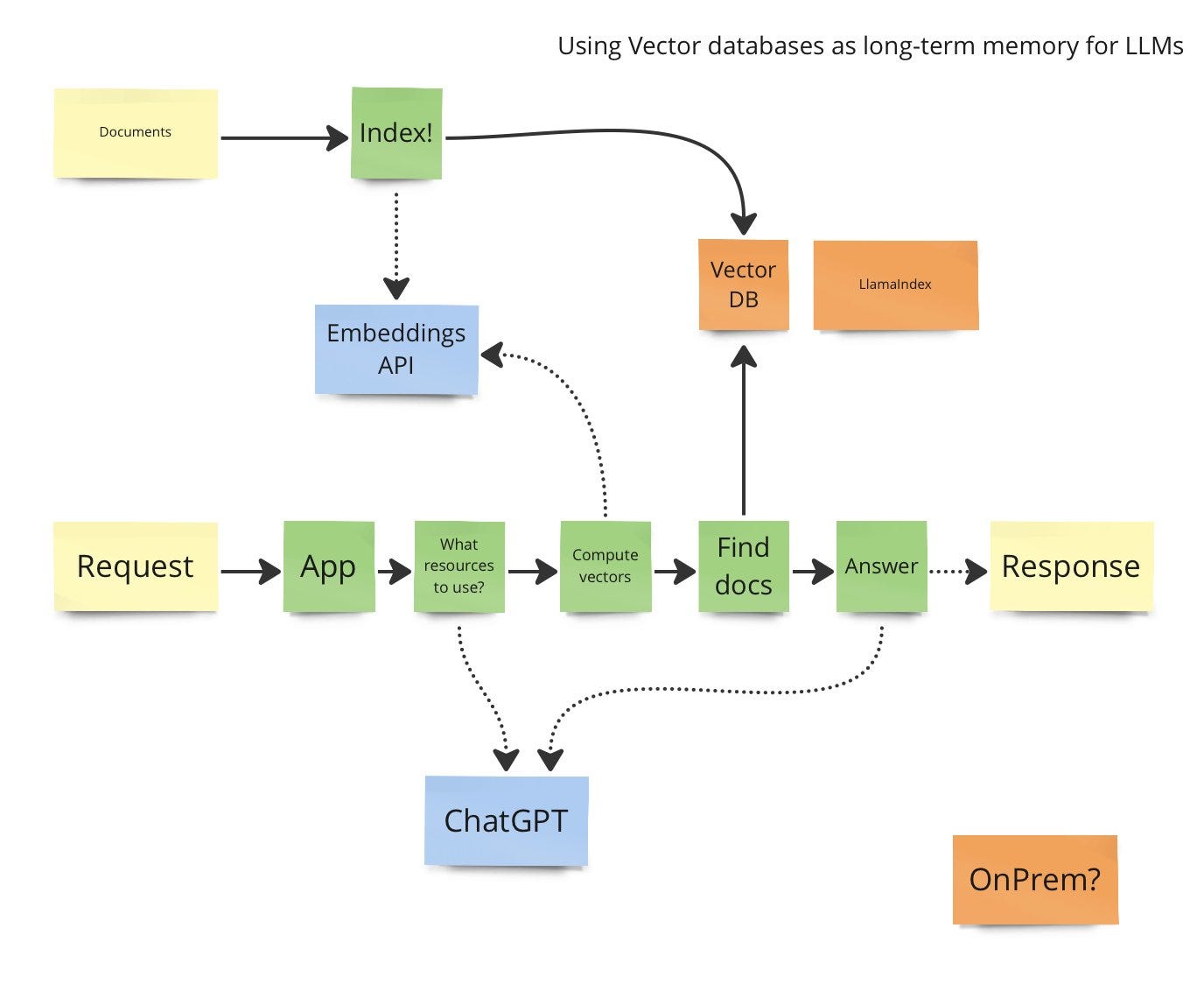
No matter what you do, I ask you to:
Read the prompt engineering guide, this will save you a ton of time!
Add UX into the product to capture user feedback in a format usable for training. Why? This data is gold. You’ll be able to fine-tune your own models later with that.
Have your engineers dive into a few examples with LangChain, memory and agents. This will expand their horizons. You wouldn’t believe how many hard tasks can now be solved with a single precise request to a large language model.
We can’t trust the cloud. How can we run everything on-the-premises?
My advice is to start prototyping solutions and products right away with Azure Open AI. Azure provides a good balance of security and compliance. They have GPT3.5, GPT4 and Ada there.
By starting to prototype right now, you can start already learning about what is possible and what capabilities are needed.
In parallel, build a suite of benchmarks that test the efficiency of your prompts (you are doing dataset-driven prompt development, right?). As soon as there is a new LLM model available, run your benchmarks against this model. Benchmarks will show exactly how good or bad is the model for your specific project.
This way you’ll be able to optimise your ML-driven products across a wide spectrum of available models: high CapEx vs OpEx, hosted vs local, precise and expensive vs good and affordable.
Chances are that different parts of your prompt pipeline could be run against different models already, to achieve the best results.
Have more questions?
First of all, just check out ML chats and forums. These questions can be already answered there. I’m gathering a lot of insights simply by engaging with experts. If you have partners or peers in your business - check up on them, chances are that they are already working on something in this area.
If you seek technical advice to speed up your own development of ML-driven products, reach to me: rinat@abdullin.com
If you are looking for a team to prototype and build a ML product for you, reach out to Trustbit: christoph.hasenzagl@trustbit.tech
Till next week!
Best regards,
Rinat